
It seems like every couple weeks there's some embarrassing failure of AI that gets quickly patched, but just because AI companies scramble to hide the failures of their technology doesn't mean they haven't failed in ways that shouldn't have been possible if they were what they claim them to be.
> I don't think there exists such a question that can fool an LLM but not fool a reasonably smart person.
An example was on the front page here just a few days ago.
https://s3.eu-central-2.wasabisys.com/mastodonworld/media_at...
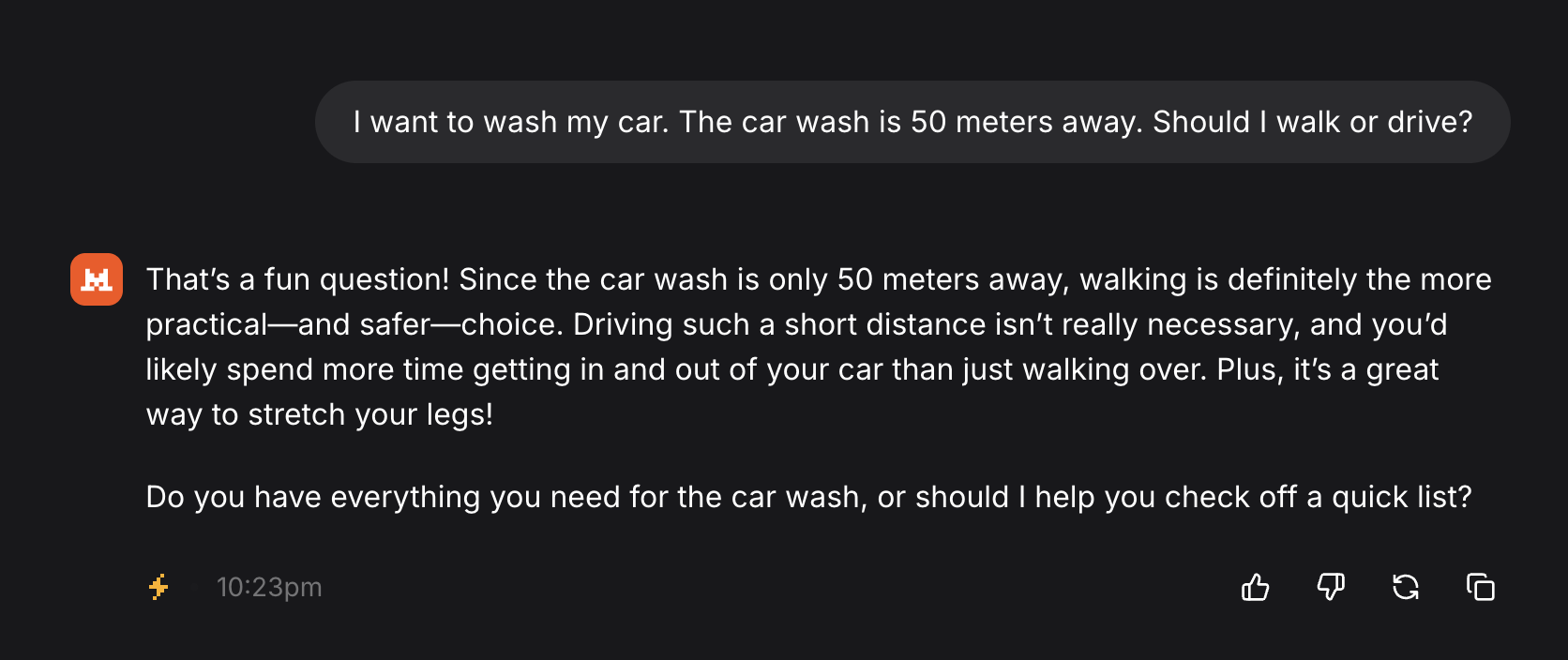{kind=link}
Until someone invents an LLM that has any actual understanding of the words it outputs (which doesn't seem likely to happen in my lifetime) these things are going to keep happening, just like how it's impossible to get them to stop hallucinating. The limitation is intrinsic to what they are. We call these chatbots AI, but there is no intelligence there that didn't come from the humans whose words were used to train them.
Every few weeks I see the same thing.
Come up with an example that trips up ChatGPT.
https://preview.redd.it/2jzzt66r5rjg1.png?width=1346&format=...
{kind=link}
In fact give it 100 tries and post here if you find even one.
If your answer is that OpenAI is constantly patching these, then that's conspiracy level thinking. But if you really want to go there, then it should be easy to come up with a new prompt to stump chatgpt wouldn't it?