
Progress. /s
> Progress. /s
pretty much, lmao. my theory is 4.6 started thinking less to save compute for 4.7 release. but who knows what's going on at anthropic
People at Anthropic, of course
This is not the first time where the more neutral (which imo is better) has caused me to be confused why everyone is saying something different in the comments.
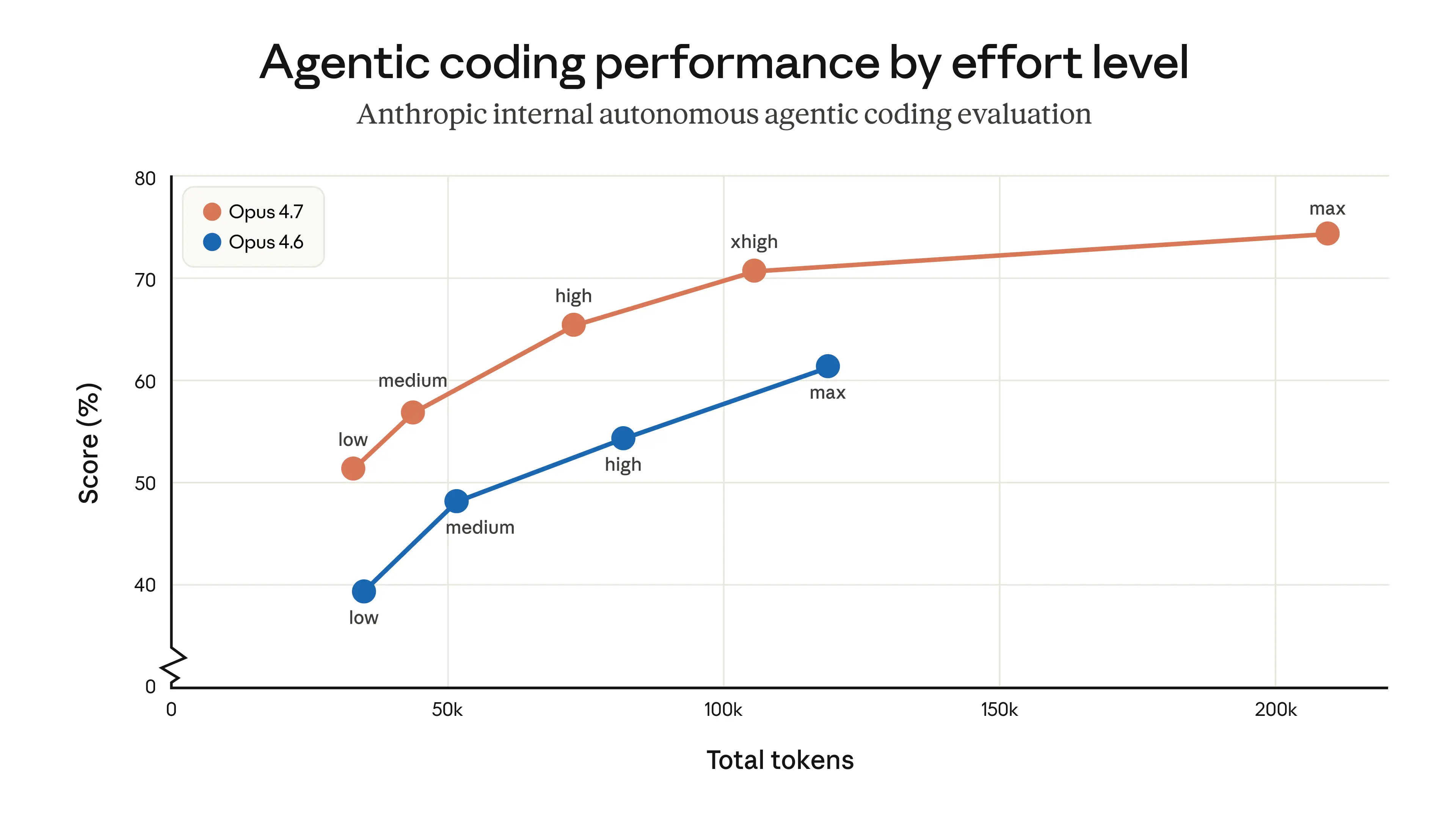
"given that Opus 4.7 on Low thinking is strictly better than Opus 4.6 on Medium, etc., etc.”
Opus 4.7 in general is more expensive for similar usage. Now we can argue that is provides better performance all else being equal but I haven’t been able to see that
https://www.anthropic.com/_next/image?url=https%3A%2F%2Fwww-...
{kind=link}
1. In my own use, since 1 Apr this month, very heavy coding:
> 472.8K Input Tokens +299.3M cached > 2.2M Output Tokens
My workloads generate ~5x more output than input, and output tokens cost 5x more per token... output dominates my bill at roughly 25x the cost of input. (Even more so when you consider cache hits!) If Opus 4.7 was more efficient with reasoning (and thus output), I'd likely save considerable money (were I paying per-token).
2. Anthropic's benchmarks DO show strictly-better (granted they are Anthropic's benchmarks, so salt may be needed) https://www.anthropic.com/_next/image?url=https%3A%2F%2Fwww-...