
Also if LLM’s weren’t really getting better in general but just benchmaxxing, then it would be extremely lucky that this also happens to be leading to a general increase in coding capabilities that have been observed in more recent models.
AI has already surpassed 99% of humans in coding in narrow domains. The question is, how wide does the domain have to be before models no longer ever surpass humans? I’d wager we’d have to wait until scaling of compute infrastructure stops, wait 6 months, then see.
Have you ever once looked at a METR chart? https://files.civai.org/assets/METR_Chart.jpg
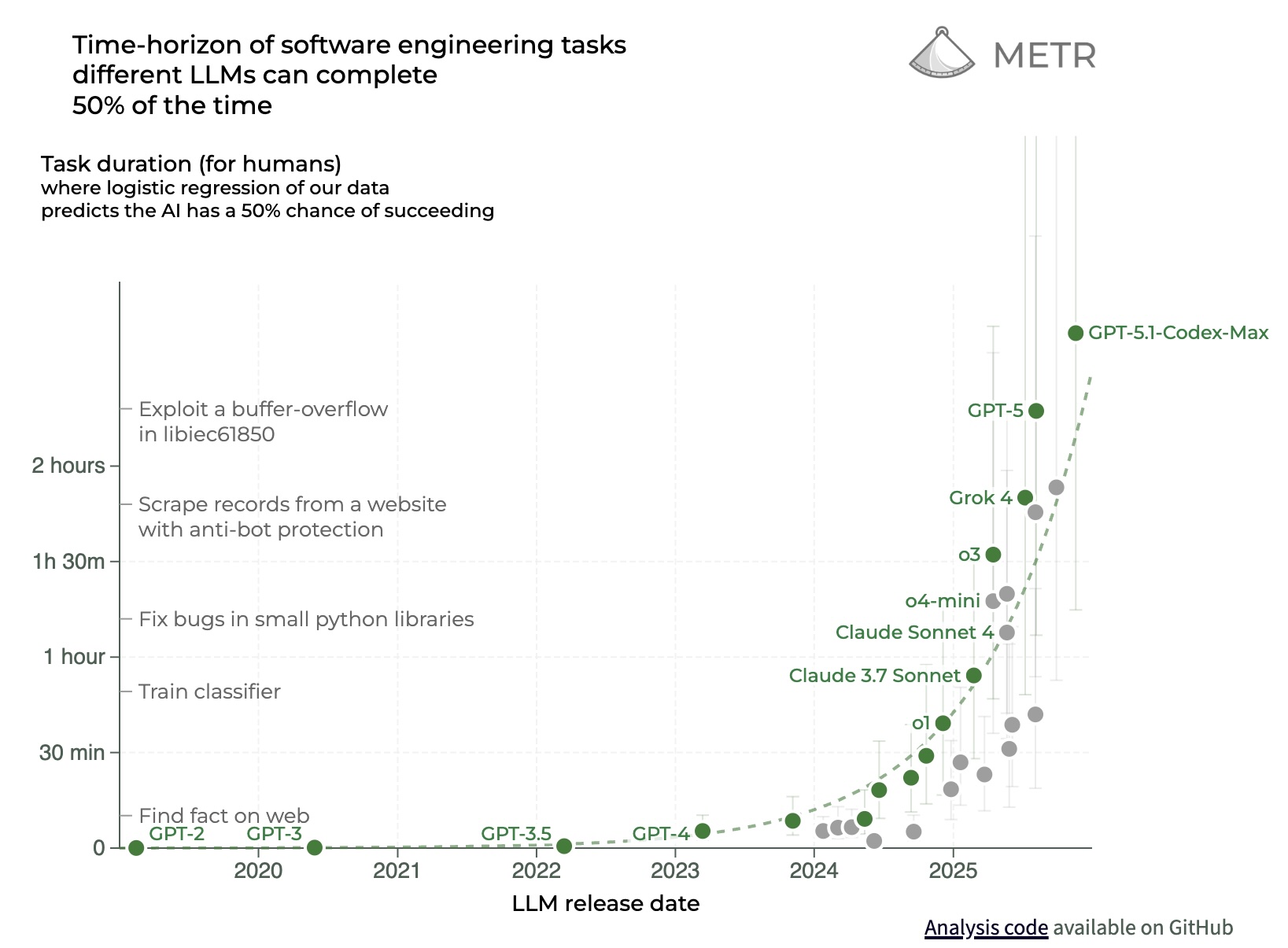{kind=link}
That's not an asymptote.
> there's also the fundamental fact that performance on benchmarks is not the same thing as performance in the real world
Again, yes, you're correct in the general case but it has very little to do with the specific case.
Would you find it convincing if I simply said "some internet arguments are wrong"? It's certainly a true statement, and you've made an internet argument here, so clearly you should accept that you're wrong, right?
I'm not "convincing" anyone of anything. I'm stating the reasons that I, personally, am unconvinced of a specific claim being made to me.