
The mallard reaction is very possible in microwaves, but they use microwave-specific crockery. I think the vision was possibly killed by people not wanting to maintain a second set of crockery.
See here for a fun write-up: https://www.lesswrong.com/posts/8m6AM5qtPMjgTkEeD/my-journey...
Perhaps we can liken these auxiliary advances to agents and harnesses in the analogy. In the end, despite the unbridled optimism from certain backers, we never solved the fundamental issue with microwaves: that they use electromagnetic waves for cooking, and that electromagnetic waves have certain undesirable properties for this application.
[0] https://americanhistory.si.edu/collections/object/nmah_10880...
Understand that a lot of people don't have a lot of choice but I use mine (actually have a 4 in 1 when I had to replace the old one after it burst into flames and that's somewhat useful as a second oven).
It just made me realize why I don't have those found memories of my mom's cooking. When we got our first microwave she went full on the vibe cooking and took years to realize how dumb it was.
I hope my kid doesn't get the same kind of memories about my weekend projects.
You are obviously right and I see examples of it everywhere.
E.g I asked Claude opus 4.7 (the latest/greatest) the other day “is a Rimworld year 60 days?”. The reply (paraphrased) “No, a Rimworld year is 4 seasons each of 15 days which is 60 days total”.
Equally, it gets confused about what is a mod or vanilla since it is just predicting based on what it read on forums, which are clearly ambiguous enough (to a dumb text predictor).
Yes. A RimWorld year is 60 days, split into four 15-day quadrums (Aprimay, Jugust, Septober, Decembary), each corresponding to a season.Can you imagine how silly they’d look when everyone realised.
If pointing out the flawed approach to making something more productive isn't productive, then what do you consider to be productive?
> Less than a decade ago the idea that a computer could take a fuzzy human-readable description and turn it into executable code was science fiction
Cobol was sold to people on the idea that anyone could create something with fuzzy human readable description that would result in executable code. That was back in the 60s.
What lessons did we learn?
1) Leaving things to the people who make fuzzy human readable descriptions turns out to be a terrible way to have things implemented.
2) Slowly and deliberately thinking things through before, during, and after implementation always leads to better results.
It's a lesson that keeps needing to be re-learned by people who don't/can't look at things through a historical lens.
It was the same with cobol, as it was with programming in spreadsheets in the 80s, as it was with the nocode movement in the 00s, as it is now again with LLMs in the 20s, and it will be again with a future generation in the 40s.
---
> As is the ability to write long form text, and be so hard to distinguish from real that placing an em dash in your text will cause an uproar on this forum.
Long form text generation that is hard to distinguish from human authored text also goes back to the 60s.
That's when we got the first instances of the Eliza effect.
> You can describe things by their fundamental functions and make many things sound elementary but I find it counter productive given the capabilities we've seen from this technology
The capabilities we've seen are:
- Text prediction/generation
- Inducing the Eliza effect
Your attempt at an analogy will make sense when someone tries to install a house as middle management at some company.
To believe that first you would have to ignore tool calling, ReAct loops, and the whole agent feature. That would be silly.
How?
It all still functions with text prediction
Wilful ignorance can't be fixed. As the saying goes, you can lead a horse to water but you can't make it drink. I can point you to ReAct loops and tool-calling and agent-based systems. If after being pointed those you still choose to be stuck on the "it's just text prediction" then that's a problem you are creating for yourself, and only you can get unstuck on a problem of your own making.
>> Wilful ignorance can't be fixed. As the saying goes, you can lead a horse to water but you can't make it drink. I can point you to ReAct loops and tool-calling and agent-based systems. If after being pointed those you still choose to be stuck on the "it's just text prediction" then that's a problem you are creating for yourself, and only you can get unstuck on a problem of your own making.
Woof, you're sounding mighty aggressive for someone with such a fundamental misunderstanding of the technology you are defending. Have you ever even actually implemented a system around an LLM, or do practice ~~voodoo~~ "prompt engineering"?
> I can point you to ReAct loops and tool-calling and agent-based systems.
Those are all implemented - quite literally - by parsing the *text* that the LLM *autocompletes* from the prompt.
Tool calling? The model emits JSON as it autocompletes the prompt, and the json is then parsed out and transformed into an HTTP call. The response is then appended to the ongoing prompt, and the LLM is called again to *autocomplete* more output.
"ReAct loops" and "agent based systems" are the same goddamn thing. You submit a prompt and parse the output. You can wrap it up in as many layers as you want but autocomplete with some additional parsing on the output is still fucking autocomplete.
If you're going to make such strong assertions, you should understand the technology underneath or you'll come off looking like a idiot.
No. Code assistants determine which tool they can execute to meet a specific goal. They pick the tool, the execute the tool (meaning, they build command line arguments, run the command line app, analyze output, assess outcome) as subtasks.
And they do it as part of ReAct loops. If the tool fails to run, code assistants can troubleshoot problems on the fly and adapt how to call then tool until they reach the goal.
Those literally work with text prediction.
If you take the text prediction out of it, nothing happens.
You stick a harness around a text predictor which then triggers the text predictor.
If you think I am missing something then please do point it out.
LLMs are the most successful form of neural network we have, and that's because they are token prediction machines. Token predictors are easy to train because we're surrounded by written text - there's data nicely structured for use as training data for token prediction everywhere, free for the taking (especially if you ignore copyright law and robots.txt and crawl the entire web).
We can't train an LLM to have a more complex internal thought loop because there's no way to synthesize or acquire that internal training data in a way where you could perform backprop training with it.
Even "train of thought" models are reducing complex thoughts to simple token space as they iterate, and that is required because backprop only works when you can compute the delta between <input state> and <desired output state>. It can't work for anything more complicated or recursive than that.
image: https://mataroa.blog/images/b5c65214.png
{kind=link}
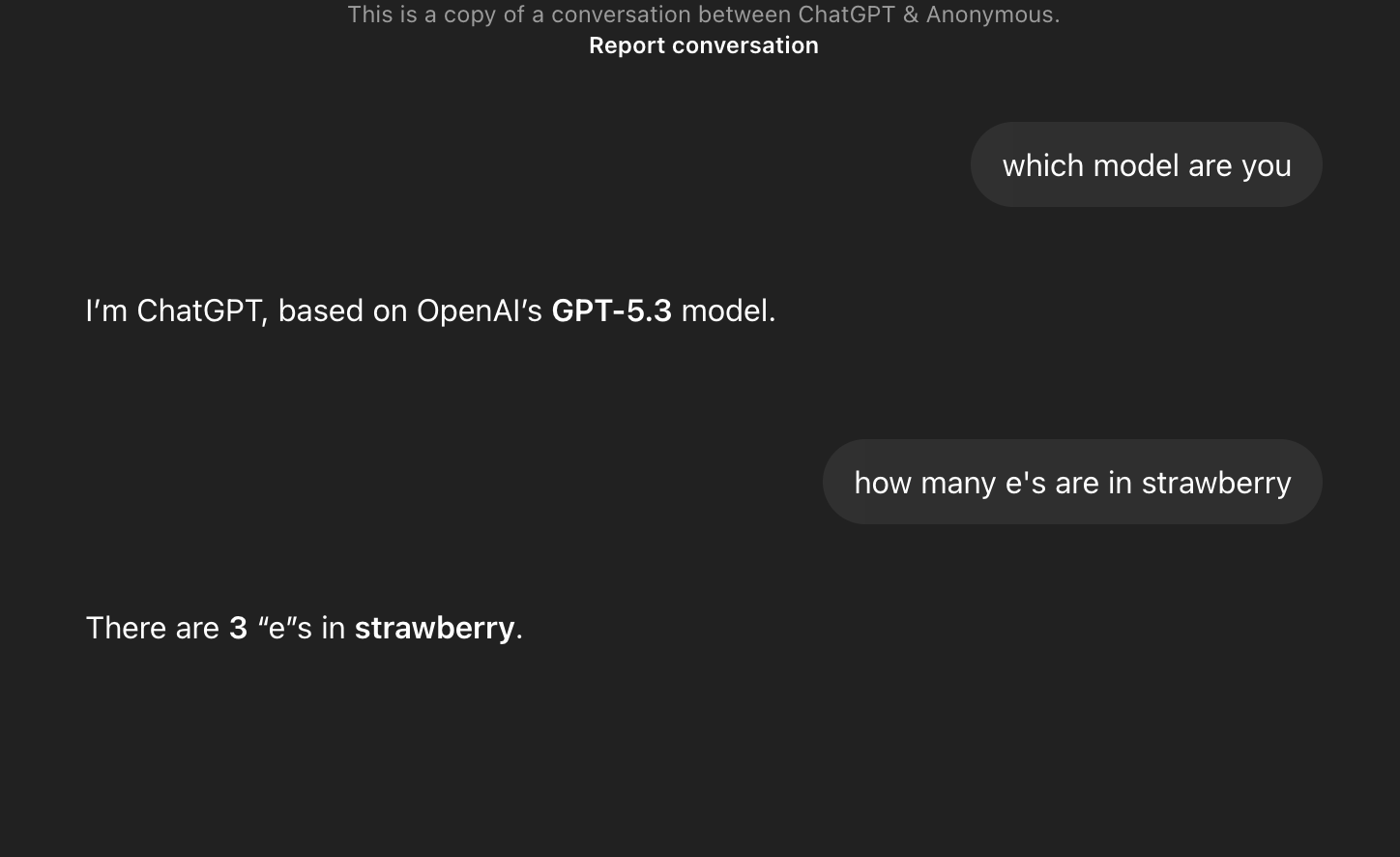
but it says that there are 3 e's in strawberry ;)
Now this is literally something which occurs because of it being text autocomplete and the inherent issue of token based Large language models. So you are literally right :D
My point is that AI can have its issues and it can have its plus points (just like text autocomplete but some suggest its on steroids)
The issue to me feels like we are hammering it in absolutely everything and anything, perhaps it should be used more selectively, y'know, like perhaps a tool?
> Mark this prediction it will happen
But this historically is a very strong predictor of a poor prediction
Gemini: There is *1* "e" in the word "strawberry".
Seems fine
See: https://fediverse.zachleat.com/@zachleat/116529994444529036
This is like saying that somebody speaking Chinese is just playing the Chinese Room [1] experiment. The only reason it's less immediately obviously absurd here is because the black box nature of LLMs obfuscates their relatively basic algorithmic functionality and let's people anthropomorphize it into being a brain.
This is not quite accurate. The human lips, throat etc have evolved to be better at producing speech, which indicates that it's not that recent. And that it was a factor in the success of groups who could do it better than others.
It likely started "no later than 150,000 to 200,000 years ago."
sources:
https://en.wikipedia.org/wiki/Origin_of_speech#Evolution_of_...
I think, therefore I am. You parrot, therefore you are... ?
Have you ever thought about how you would determine if an arbitrary given entity is intelligent or not? I think you'll agree it would require some kind of test. You might agree that the test would have to involve bidirectional interaction (since otherwise it would be impossible to distinguish an actual person from a recording of one).
Last year this level of ignorance and cluelessness was amusing. Nowadays it's just sad and disappointing. It's like looking at a computer and downplaying it as something that just flips switches on and off.
It will be interesting in the next few years. Assuming we won't be in the 3rd world war thanks to the USA and will have much bigger concerns.
You're grossly inflating the level of contribution from your average software developer. Are we supposed to believe that the same people who generated the high volume of mess that plagues legacy systems are now somehow suddenly exemplary craftsmen?
Also, it takes a huge volume of wilful ignorance and self delusion to fool yourself into believing that today's vibecoders are anyone other than yesterday's software developers. The criticism you are directing towards vibecoding is actually a criticism of your average developer's output reflecting their skill and know-how once their coding output outpaces or even ignores any kind of feedback from competent and experienced engineers.
What I see is a need to shit on a tool to try to inflate your sense if self worth.
The ones who never acknowledge a mistake even if the process is crashing; the ones who put "return true" in a test so that the test doesn't execute and will insist that you broke their code if you remove the return true and when the test actually runs it fails; the ones who read a blog post about some new thing and decide we need to do like that; the ones who will write code that fails and then be nowhere to be seen when there is customer support to do.
Trying to portray everyone who ever used a tool as the incompetent cohort is an exercise in self-delusion.
Gitlab has been strapped for cash and desperately seeking a buyer to cash out for years.
If anything, the LLM revolution represents an opportunity that Gitlab is failing to capitalize upon. They have a privileged position to develop pick axes for this gold rush, but apparently they are choosing to dismiss themselves from the race altogether.
Gitlab's decision is being taken in spite of LLMs, not because of them. Enough of this tired meme.
It that scrapes Hn it works. Ironically, it's why I'm here.