
At the end of the day, as a consumer, you still pay per token (or per something) to your provider, except you can chose from multiple providers with your own criteria. If you want to use DeepSeek v4 hosted in Europe, it's possible.
Which would also be an ideal outcome for people interested in avoiding a concentration of power and wealth due to access to generative AI.
Open models that are competitive with frontier will be used on shared hosts.
And with the extreme chip shortages for the next two years, there's little appetite for even bigger models anyway.
Barring a breakthrough in scaling, the only direction the models can really go is smaller. Which will inevitably mean better performing local models for same chip budget.
You can always run these models cheaper locally if you're willing to compromise on total throughput and speed of inference. For most end-user or small-scale business needs, you don't really need a lot of either.
Before you challenge with benchmarks, consider the labs which release open weight models have internal testing and unpublished results.
1. Your European startup will be competing with others using a much better frontier model. In a scenario where you already have other major disadvantages (access to capital, labor), you might be outcompeted
2. Open models have been keeping pace very nicely, but they rely on distillation of frontier models. If the race gets really tight, this could be affected so that the time gap grows larger (ie, it's very unlikely anyone but Anthropic is distilling from Mythos at the moment)
If the small (and I'd even say, sometimes imperceptible) difference between Opus & DeepSeek v4 Pro is such a disadvantage for your startup, it's that your startup have an issue, not the LLM.
At the end of the day, your startup is there to solve real problems and even before the LLMs, being fast at coding things have never been such a huge competitive advantage compared to marketing, sales, customer support, product vision ...
Besides, if the difference between Opus and DeepSeek 4 is so small and imperceptible, you are missing the opportunity to launch a startup on your own and compete with Claude Code.
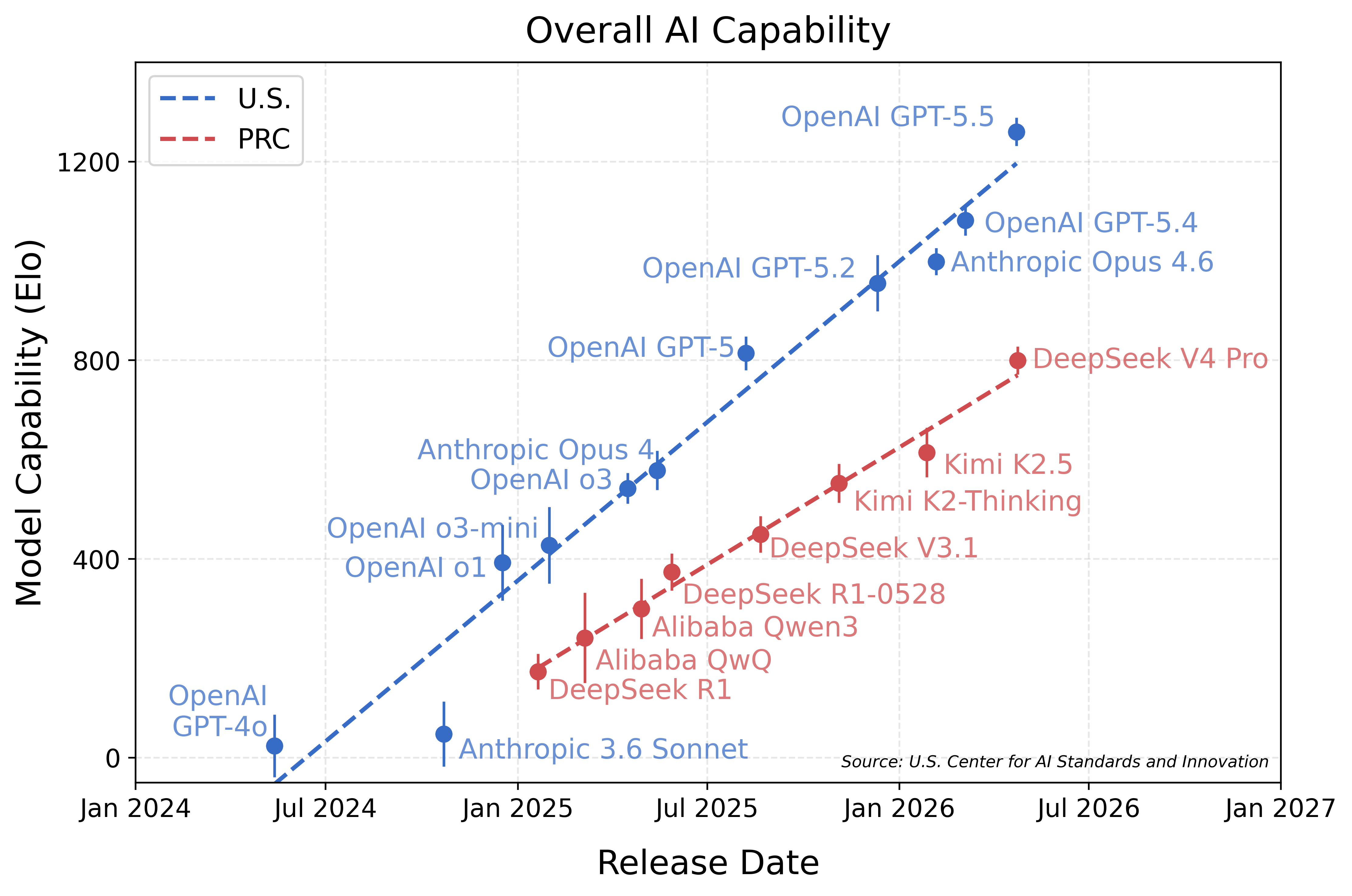
Update: GPT-5.5 found it.
Article: https://www.nist.gov/news-events/news/2026/05/caisi-evaluati...
Graph: https://www.nist.gov/sites/default/files/images/2026/05/01/1...
{kind=link}
If the Chinese government published a graph that said the opposite, would you consider that a serious and objective source?
edit: I'm specifically referring to the "5.5 Pro" model, not regular 5.5 with Pro tier subscription. Claude has no model available that's comparable to 5.5 Pro either.
The thing is, vast majority of code tasks aren’t a venture into the unknown. We as an industry for the most part build CRUD interfaces and dashboards. That can be achieved, with supervision, with frontier open-weights models quite well.
Well, yes, someone probably will do that. But I’m pretty sure there will be consequences for the engineer errors in this vibe-calculations.
(tap view all on yr link or ask gpt to search for you next time)