
The most common first thing to cache is getting the current user, because this ends up being a very hot path for most stateless systems. Because you need to get the current user for almost every request, it's quite easy for getting the current user to be 50% of database load: first you get the user, then you do the thing. tada, user lookup is now half your app by volume
Look at this image: https://cs61.seas.harvard.edu/site/img/storage-hierarchy.png
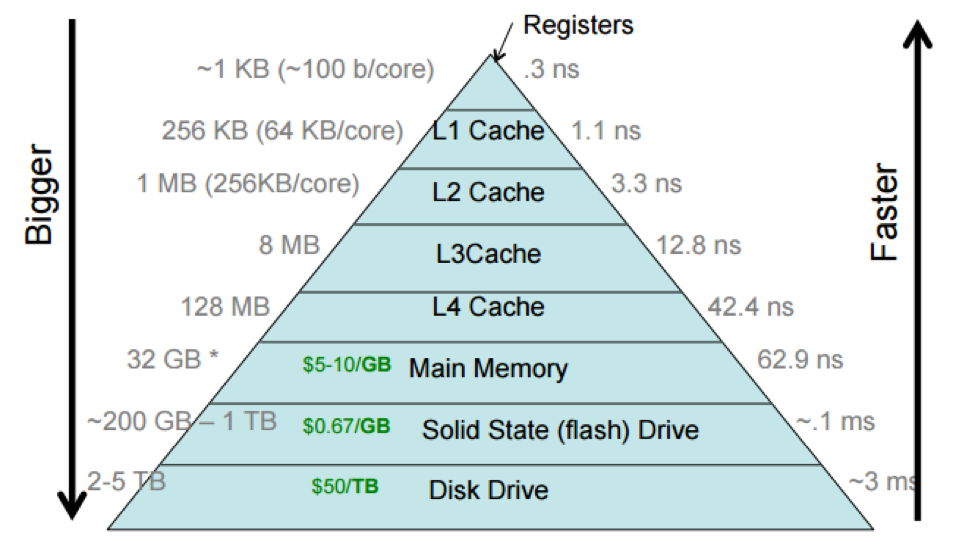{kind=link}
At scale, the timing and order of magnitude increases in latency can add up. Caching the most requested data the higher you go can keep up performance (at added cost). On a busy website, that could be things like session tokens or other data that is part of every request. On a landing page, it could be images or other static data (I mean, you'd use a CDN for this, but you get the idea). Database calls can be expensive (computationally and IO wise), so if you can recalculate and cache certain operations, you can keep up.
Also, do you really need memcached/redis? If you have session affinity, you can also have nodes each keep their own caches in memory, with the caveat that if there's a failover, you'll have to re-fetch the data. Redis/memcached would be more of a shared cache, for things that you may not want to interrupt the user if they hit a different front-end endpoint.
It also doesn't have to be a cache. We've used redis for distributed task coordination as a shared state with the caveat that if something happened to redis, we'd just restart the task.
TL;DR If you need a SHARED cache when the performance of your app slows down enough that the cost of caching makes up for it.