
(theopenreader.org)
Some slides with more info: https://indico.cern.ch/event/1496673/contributions/6637931/a... The approval process for a full paper is quite lengthy in the collaboration, but a more comprehensive one is coming in the following months, if everything went smoothly.
Regarding the exact algorithm: there are a few versions of the models deployed. Before v4 (when this article was written), they are slides 9-10. The model was trained as a plain VAE that is essentially a small MLP. In inference time, the decoder was stripped and the mu^2 term from the KL div was used as the loss (contributions from terms containing sigma was found to be having negliable impact on signal efficiency). In v5 we added a VICREG block before that and used the reconstruction loss instead. Everything runs in =2 clock cycles at 40MHz clock. Since v5, hls4ml-da4ml flow (https://arxiv.org/abs/2512.01463, https://arxiv.org/abs/2507.04535) was used for putting the model on FPGAs.
For CICADA, the models was trained as a VAE again, but this time distilled with supervised loss on the anomaly score on a calibration dataset. Some slides: https://indico.global/event/8004/contributions/72149/attachm... (not up-to-date, but don't know if there other newer open ones). Both student and teacher was a conventional conv-dense models, can be found in slides 14-15.
Just sell some of my works for running qat (high-granularity quantization) and doing deployment (distributed arithmetic) of NNs in the context of such applications (i.e., FPGA deployment for <1us latency), if you are interested: https://arxiv.org/abs/2405.00645 https://arxiv.org/abs/2507.04535
Happy to take any questions.
I have since pivoted a lot of my PhD work (still related the HLS and EDA). But I wonder what is the current main limitation/challenges of building these trigger systems in hardware today. For example, in my mind it seems like the EDA and tooling can be a big limitation such as reliance on commercial HLS tools which can be buggy, hard to use, and hard to debug. From experience, this makes it harder to build different optimized architectures in hardware or build co-design frameworks without having high HLS expertise or putting in a lot of extra engineering/tooling effort. Also tool runtimes make the design and debug cycle longer, especially if you are trying to DSE on post-implementation metrics since you bring in implementation tools as well.
But I might be way off here and the real challenges are with other aspects beyond the tools.
The problems you described here are pretty much precise. In the past, and mostly now, we are replying on the commercial Vivado/Vitis HLS toolchains for the deployment of these networks through hls4ml, a template based compiler of the quantized models to the HLS projects. For this class of fully parallel (II=1) models, the tools usually give fine results, but indeed can be wrong sometimes (great recent example from our college's post: https://sioni.web.cern.ch/2026/03/24/debugging-fastml).
Tool runtime is another issue. For the models discussed in this post, they are not larger than ~30K LUTs, and with the low complexity (~dense only), synthesis time was fine. But for larger ones, like the ones here (https://arxiv.org/abs/2510.24784), it can take up to... a week for one HLS compilation while eating ~80G ram. Can get worse if time multiplex is in place things like #pragma HLS dataflow is used...
Personally, I do not usually DSE on post implementation/HLS results, since for the unrolled logic blocks, ok-ish performance model can be derived obtained w/o doing the synthesis (via ebops defined in HGQ, or better if using heuristics based on the rough cost of low level operations the design will translate to). But there are works doing DSE based on post HLS results (https://arxiv.org/pdf/2502.05850, real vitis synth), or using some other surrogate to get over the problem (e.g., https://arxiv.org/abs/2501.05515, using bops). High-level surrogate models are also being developed (https://arxiv.org/pdf/2511.05615).
We are also trying to get alternatives to the commercial HLS toolflows. For instance, I'm working on the direct to RTL codegen (da4ml) way (optionally via XLS), and the current work-in-progress is at https://github.com/calad0i/da4ml/tree/dev, if you are interested: all combinational or fully pipelined things are supported with reasonable performance model (~10% err in LUTs and ~20% err in latency), but multicycle, or stateful design generations still need a lot of manual intervention (not automated), which are to be implemented in the future. Since at some stages of the trigger chain, the system is/will be time-multiplexed, such functionality will be needed in the future.
Other works on this direction includes adding new backends to hls4ml that are oos (e.g., openhls/XLS), or other alternatives like chisel4ml (https://github.com/cs-jsi/chisel4ml). Hopefully, we will be no-longer reliant on the commercial tools till RTL for the incoming upgrade. That being said, Vivado still appears to be the only choice for the post RTL stages for us.
https://arxiv.org/html/2411.19506v1
Why is it so hard to elaborate what AI algorithm / technique they integrate? Would have made this article much better
Already the case with consulting companies, have seen it myself
I do know about linear regression even had quite some of it at university.
But I still wouldn’t be able to just implement it on some data without good couple days to weeks of figuring things out and which tools to use so I don’t implement it from scratch.
let v0 = 0
let v1 = 0.40978399*(0.616*u + 0.291*v)
let v2 = if 0 > v1 then 0 else v1
let v3 = 0
let v4 = 0.377928*(0.261*u + 0.468*v)
let v5 = if 0 > v4 then 0 else v4... // inputs: u, v
// --- hidden layer 1 (3 neurons) ---
let v0 = 0.616*u + 0.291*v - 0.135
let v1 = if 0 > v0 then 0 else v0
let v2 = -0.482*u + 0.735*v + 0.044
let v3 = if 0 > v2 then 0 else v2
let v4 = 0.261*u - 0.553*v + 0.310
let v5 = if 0 > v4 then 0 else v4
// --- hidden layer 2 (2 neurons) ---
let v6 = 0.410*v1 - 0.378*v3 + 0.528*v5 + 0.091
let v7 = if 0 > v6 then 0 else v6
let v8 = -0.194*v1 + 0.617*v3 - 0.291*v5 - 0.058
let v9 = if 0 > v8 then 0 else v8
// --- output layer (binary classification) ---
let v10 = 0.739*v7 - 0.415*v9 + 0.022
// sigmoid squashing v10 into the range (0, 1)
let out = 1 / (1 + exp(-v10))is there something 'less good' about:
let v1 = if v0 < 0 then 0 else v0
Is Yoda condition somehow better?
Shouldn't we write: Let v1 = max 0 v0
From around when the term was first coined: "artificial intelligence research is concerned with constructing machines (usually programs for general-purpose computers) which exhibit behavior such that, if it were observed in human activity, we would deign to label the behavior 'intelligent.'" [1]
At some point someone will realise that backpropagation and adjoint solves are the same thing.
[1] https://archive.ics.uci.edu/ml/datasets/HIGGS
In my experiments, linear regression with extended (addition of squared values) attributes is very much competitive in accuracy terms with reported MLP accuracy.
https://opendata-qa.cern.ch/record/93940
if you can beat it with linear regression we'd be happy to know.
It’s impressive, honestly.
https://news.ycombinator.com/item?id=12340348 Neural network spotted deep inside Samsung's Galaxy S7 silicon brain (2016)
https://ieeexplore.ieee.org/document/831066 Towards a high performance neural branch predictor (1999)
It's not about linear algebra (which is just used as a way to represent arbitrary functions), it's about data. When your problem is better specified from data than from first principles, it's time to use an ML model.
And for historians: Delphi people (amongst others) had papers on Higgs selection using (A)NN from LEP data (overfit :) , obviously without the 5 sigma. It was an argument for LHC.
Dear downvoters/shadowbanners: do your homework.
https://www.youtube.com/watch?v=8IZwhbsjhvE (From Zettabytes to a Few Precious Events: Nanosecond AI at the Large Hadron Collider by Thea Aarrestad)
Page: https://www.scylladb.com/tech-talk/from-zettabytes-to-a-few-...
(Probably not for this here though.)
- FPAGs like this one are generally COTS.
- All the experiments use GPUs which come straight from the vendors.
- Most of the computing isn't even on site, it's distributed around the world in various computing centers. Yes they also overflow into cloud computing but various publicly funded datacenters tend to be cheaper (or effectively "free" because they were allocated to CERN experiments).
Some very specific elements (those in the detector) need to be radiation hard and need O(microsecond) latency. These custom electronics are built all over the world by contributing national labs and universities.
CERN builds a bit.
It is a project bureau. Everything is essentially outsourced, leaving a management shell institute to parade for VIPs. Actually they are close to completely forgetting what they already knew in the hard sciences domain.
Who says CERN needs to be cost effective?
I was just answering this question. LLM logic in weights is fundamentally from machine learning, so yes. Wasn't really saying anything about the article.
Much of the early AI research was spent on developing various algorithms that could play board games.
Didn't even need computers, one early AI was MENACE [1], a set of 304 matchboxes which could learn how to play noughts and crosses.
[1] https://en.wikipedia.org/wiki/Matchbox_Educable_Noughts_and_...
I didn't know what a Jujube was, but I got the idea.
So they aren't "burned into silicon" then? The article mentions FPGAs and ASICs but it's a bit vague. I would be surprised if ASICs actually made sense here.
> To meet these extreme requirements, CERN has deliberately moved away from conventional GPU or TPU-based artificial intelligence architectures.
This isn't quite right either: CERN is using more GPUs than ever. The data processing has quite a few steps and physicists are more than happy to just buy COTS GPUs and CPUs when they work.
Isn’t this kind of approach feasible for something so purpose-built?
> CERN is using extremely small, custom large language models physically burned into silicon chips to perform real-time filtering of the enormous data generated by the Large Hadron Collider (LHC).
> This work represents a compelling real-world demonstration of “tiny AI” — highly specialised, minimal-footprint neural networks
FPGAs for Neural Networks have been s thing since before the LLM era.
> [ GENEVA, SWITZERLAND — March 28, 2026 ] — CERN is using extremely small, custom large language models physically burned into silicon chips to perform real-time filtering of the enormous data generated by the Large Hadron Collider (LHC).
Like (~9K) Jumbo Frames!
I hacked on it a while back, added Comv2dTranspose support to it.
Like anything else, once you work with a system, it gives you ten ideas where to go next...
Are you perhaps confusing Groq with the Etched approach? IIUC Etched is the company that "burned the transformer onto a chip". Groq uses LPUs that are more generalist (they can run many transformers and some other architectures) and their speed comes from using SRAM.
Some tried to hold out and keep calling it "ML" or just "neural networks" but eventually their colleagues start asking them why they aren't doing any AI research like the other people they read about. For a while some would say "I just say AI for the grant proposals", but it's hard to avoid buzzwords when you're writing it 3 times a day I guess.
Although note that the paper doesn't say "AI". The buzzword there is "anomaly detection" which is even weirder: somehow in collider physics it's now the preferred word for "autoencoder", even though the experiments have always thrown out 99.998% of their data with "classical" algorithms.
I think a better question would be "when are FPGAs going to stop being so ridiculously overpriced". That feels more possible to me (but still unlikely).
5 years ago we would've called it a Machine Learning algorithm. 5 years before that, a Big Data algorithm.
> 5 years before that, a Big Data algorithm.
The DNN part? Absolutely not.
I don’t know why people feel the need for such revisionism but AI has been a field encompassing things far more basic than this for longer than most commenters have been alive.
When I was 13, having just started programming, I picked up a book from a "junk bin" at a book store on Artificial Intelligence. It must have been from the mid-80s if not older.
It had an entire chapter on syllogism[1] and how to implement a program to spit them out based on user input. As I recall it basically amounted to some string exteaction assuming user followed a template and string concatenation to generate the result. I distinctly recall not being impressed about such a trivial thing being part of a book on AI.
In the 1990s I remember taking my friend's IRC chat history and running it through a Markov model to generate drivel, which was really entertaining.
> The AXOL1TL V5 architecture comprises a VICReg-trained feature extractor stacked on top of a VAE.
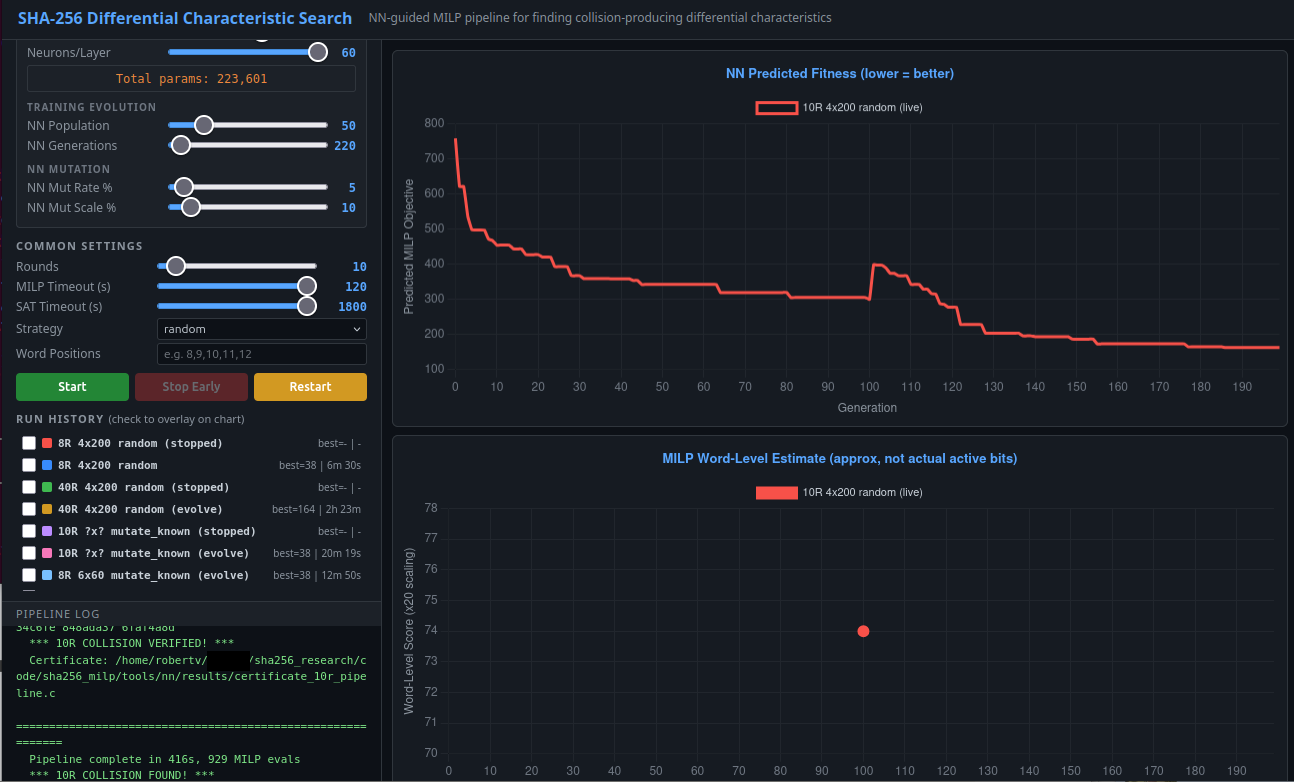
After training it fully, we moved on to the inference stage, trying it on the round counts we didn't have data for! It turned out ... to have zero predictive ability on data it didn't see before. This is on well-structured, sensible extrapolations for what worked at lower round counts, and what could be selected based on real algabraic correlations. This mini neural network isn't part of our pipeline now.
[1] screenshot: https://taonexus.com/publicfiles/mar2026/neural-network.png
{kind=link}