
All I would need from an LLM doubter is evidence that at tractable software engineering task LLM's are not improving. The strongest argument against the increasing general capabilities of LLM's are the ARC-AGI tasks, however the creators admit that each generation of LLM's exceed their expectations, and that AGI will be achieved within the decade.
That being said, I don't even think that arguing about this from a mathematical perspective is a worthwhile use of time. Calling something an asymptote in the first place requires defining a quantifiable "X" and "Y", which we don't even have. What we have are a bunch of synthetic benchmarks. Even ignoring the fact that the answers to the questions are known to regularly leak into the training data (in other words, it's possible for scores to increase while capabilities remain the same), there's also the fundamental fact that performance on benchmarks is not the same thing as performance in the real world. And being able to answer some arbitrary set of arbitrary questions on a benchmark which the previous model couldn't, does not have a quantifiable correlation to some specific amount of real-world improvement.
The OP article focuses on research papers which assess real-world impact of LLMs within software organizations, which I think are more representative.
I wouldn't call myself an "AI doubter" - I use LLMs every day. When you say "doubter" you're not referring to "AI" in general, or the fact that AI is helpful or boosts productivity (which I believe it does). You're rather referring to the very specific, very extraordinary claim, that LLMs will surpass humans in coding. If that's the case then yeah I'm a doubter, at least on any foreseeable timescale.
Also if LLM’s weren’t really getting better in general but just benchmaxxing, then it would be extremely lucky that this also happens to be leading to a general increase in coding capabilities that have been observed in more recent models.
AI has already surpassed 99% of humans in coding in narrow domains. The question is, how wide does the domain have to be before models no longer ever surpass humans? I’d wager we’d have to wait until scaling of compute infrastructure stops, wait 6 months, then see.
Have you ever once looked at a METR chart? https://files.civai.org/assets/METR_Chart.jpg
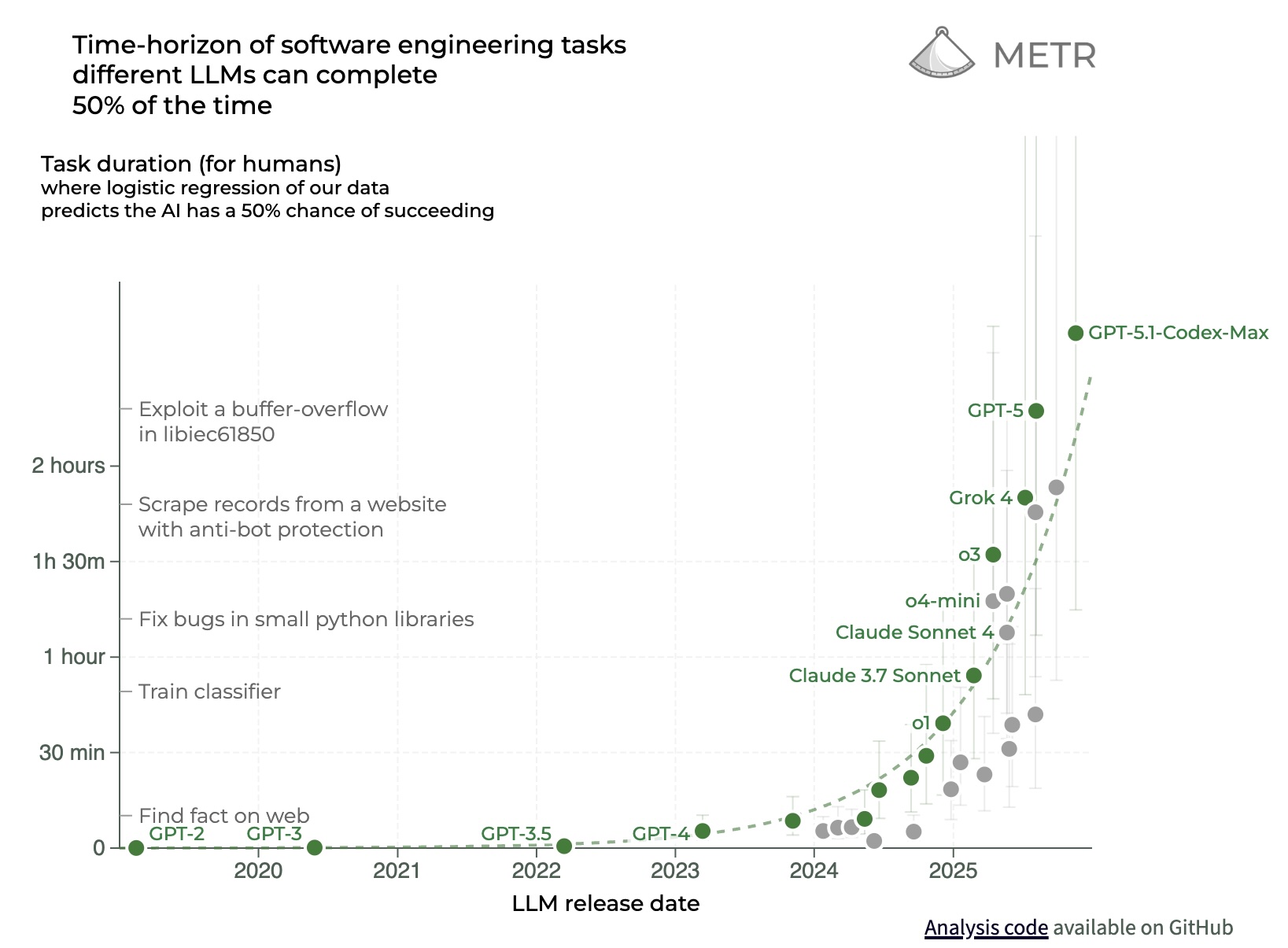{kind=link}
That's not an asymptote.
> there's also the fundamental fact that performance on benchmarks is not the same thing as performance in the real world
Again, yes, you're correct in the general case but it has very little to do with the specific case.
Would you find it convincing if I simply said "some internet arguments are wrong"? It's certainly a true statement, and you've made an internet argument here, so clearly you should accept that you're wrong, right?
I'm not "convincing" anyone of anything. I'm stating the reasons that I, personally, am unconvinced of a specific claim being made to me.
You’re definitely right that people adopt agentic workflows and are disappointed or worse, but the point is the disappointment has already reduced substantially and will continue to do so. We know this because we know the scaling laws, and also because learning theory has been around for many decades.
I'll give you the coding harnesses themselves are better because that was a new product category with a lot of low-hanging fruit, but have the models actually improved in a way that isn't just benchmaxxing? I'd argue the models seem to be regressing. Even the most AI-pilled people at my company have all complained that Opus 4.7 is a dud. Anecdotally, GPT 5.5 seems decent, but it's rumored to be a 10T parameter model, isn't noticeably better than 5.4 or 5.3, is insanely expensive to use, and seems to be experiencing model collapse since the system prompt has to beg the thing to not talk about goblins and raccoons.
> I don't find $MODEL useful
> CLEARLY you're doing it wrong
It's so dumb.
(I write code w/ agents btw, I'm just also skeptical)
"i am alive"
OH MY GOD!!
- AI coding is a disappointing fad (“fever dream?”). - that has not made meaningful progress in…6 months? - coding harness is improving - model improvements are lies: it’s just businesses “benchmaxxing” and misleading people. Real performance has not meaningfully improved - “opus 4.7 is a dud” - 5.5 suffering from “system collapse” (I’ve never heard this term before)
Since you asked and I assume you are rational and really are interested to know:
- we have many measures of performance and have studied how one particularly important but unintuitive measure (pertaining perplexity) scales with data, compute, and model size. These laws continue to hold and have satisfying theoretical origins.
- whatever the scale of 5.5, consider we have far more room to go on the scaling front. Probably another 2-3 orders of magnitude before we hit limiting bottlenecks.
- that’s also fine because scaling is only part of the puzzle. RL on verifiable rewards is virtually guaranteed to get you optimal performance and that’s the entirety of the excitement around coding agents
- while you are right about benchmarks and measurement science having a ton of weaknesses, they are not at all garbage. There are probably around 40,000 benchmarks in the literature (this is not a made up number by the way it really is around that many). Epoch made a great composite measure using good stats (IRT) called their epoch capability index, METR has done and redone their time horizon measure and it holds up beautifully. There is a ton of signal in many benchmarks and they all tell a pretty compelling story.
- additionally, this is not some unknowable thing. It strikes me as odd that people’s prior on HN a lot of time is “it’s all dumb rich people putting way too much dumb money in this”. Sorry but the world is not that dumb. Trillions of CapEx is usually pretty rationally allocated. And it is!
- why? Because this is already known what happens when you do what we’re doing. When you have a verifiable reward system, have a certain amount of compute available, have seed data to get you to where you can do RL, you will be almost guaranteed to get superhuman performance
We're almost 6 months into all this AI-code madness and I've yet to see that "rapid improvement" you mention. As in software products that are genuinely better compared to 6 months ago, or new software products (and good software products at that) which would have not existed had this AI craze not happened.
I really value skeptical people and skepticism generally. But what I think skeptical people would prefer to consider themselves is: rational and reasonable, with their beliefs well calibrated.
You’re not the only one to think that literally nothing major or significant has happened with AI but that’s simply wrong. Every major tech company - the ones poised to get the first best rewards, have already gotten good incremental revenue from AI via ads ranking/recommendations (Google, Meta, etc.), good productivity increases due to scale of workforce and advanced in house tooling. You won’t see these numbers and you don’t have to believe them. But I have seen them and I believe them, and I, like you, hate bullshit.
That's just software evolving. It happened before LLMs, it would happen without LLMs.
> good productivity increases due to scale of workforce and advanced in house tooling.
Exactly same case.
Six months after the internet was invented, you could send email between a few universities.
Six months after the computer was invented, they still hadn't actually built one.
The first transcontinental railroad, took about six YEARS just to build.
If you want to set GPT as the target, that's even easier! In that decade it has passed the Turing Test, solved novel open math problems, generates audio, video, and music, and can write coherent code. Again, there is no technology that has improved more rapidly than LLMs.
It's the "YOLO" of business strategies.
L(N,D) ~= 1.69 + 406 / N^0.339 + 411 / D^0.285
L is loss (pre training test loss) D is the scale of the data N is the number of model parameters